Member-only story
ARM vs RISC-V Vector Extensions
A comparison of the RISC-V vector extension (RVV) and ARM scalable vector extension (SVE/SVE2).

Microprocessor with vector instructions is going to be the big thing for the future. Why? Because self-driving, speech recognition, image recognition are all based on machine learning and machine learning is all about matrices and vectors.
But that is not the only reason. We have been banging our heads in the wall trying to eke out more performance for years ever since we semi-officially declared Moore’s laws to be over. In the golden old days of microprocessor design, we could simply double the clock frequency of the CPU each year and boom everybody was happy. That wonderful old trick is over.
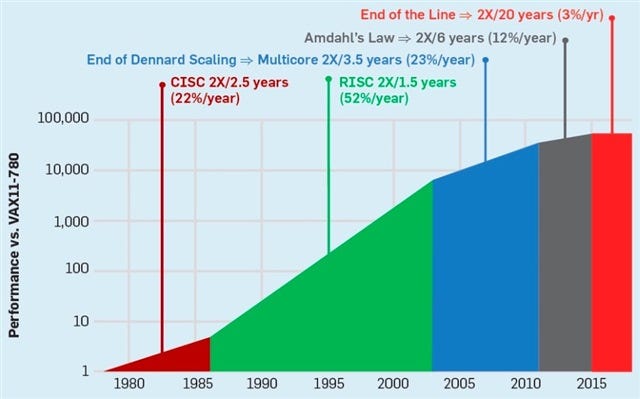
Today we play a thousand different clever games to eek out more performance whether that is through adding more CPU cores, adding out-of-order execution, more advance branch predictors or SIMD instructions.
All of these tricks really boil down to one central idea: Trying to find ways of doing work in parallel. Whenever you loop over an array of elements and do some computation on each of these elements, you have an opportunity for data-parallelism. This loop could with clever compilers be turned into a bunch of SIMD or vector instructions.

SIMD instructions such as Neon, MMX, SSE2 and AVX have worked great in multimedia applications. Doing things like video-encoding e.g. But we need to to squeeze out more performance in more areas. Vector instructions offer a lot more flexibility in taking almost any loop and turning it into vector instructions. However there are lots of different ways of going about this.
I covered RISC-V vector instructions here: RISC-V Vector Instructions vs ARM and x86 SIMD.
Lately I covered ARM vector instructions: ARMv9: What is the Big Deal?.
