You're reading for free via Erik Engheim's Friend Link. Become a member to access the best of Medium.
Member-only story
RISC vs CISC Microprocessor Philosophy in 2022
A new look at the RISC vs CISC debate by framing it as a debate on how to spend a limited transistor budget to achieve performance.

PEOPLE LIKE to think about the distinction between RISC and CISC processors as being about some specific set of features or some magical limit on number of instructions or transistors.
Few Instructions Doesn’t Mean RISC
Let us get some very obvious misconceptions out of the way. Because RISC stands for Reduced Instruction Set Computer, there are a lot of people who think a RISC processor is simply a CPU with few instructions. If that was the case then the 6502 processor would have been one of the most RISCy processor ever with mere 56 instructions. Even the Intel 8086 would count as a RISC processor as it only had 81 instructions. Even the later Intel 80286 has only around 100 instructions.
A simple 8-bit RISC processor like the AVR has 78 instructions. If you look at one of the first 32-bit RISC processors such as the PowerPC 601 (released in 1993) it had 273 instructions.
The MIPS32 instruction-set which derives from the original RISC processor at Berkley also has over 200 instructions.
We can compare this with a CISC 32-bit processor like the 80386 which only has a bit over 170 instructions. Although the MIPS R2000 processor released at a similar time (1986) had around 92 instructions.
For the curios:
Few Transistors Doesn’t Mean RISC
Here is a fun exercise, go to this wikipedia article: Transistor count.
What is the cutoff point in number of transistors between CISC and RISC processors? Oh, you cannot find one? That is because there is none. The 6502 has 4,528 transistors. While the first ARM processor has 25,000 transistors.
Or how about this fun little fact. The Motorola 68060 which is considered one of the most CISCy processors from its era weighs in at 2.5 million transistors, which is less than the 2.8 million transistors of the IBM PowerPC 601 released in the very same year 1994.
If you look at the RISC and CISC processor released around the same time there is no clear trend showing that RISC processor have fewer transistors and fewer instructions than their CISC counterparts.

So let us conclude that there is no magic number of transistors or instructions which make your chip magically turn into RISC or CISC chip. But then the question remains, what exactly makes a microprocessor RISC or CISC?
RISC and CISC are Different Transistor Budgeting Philosophies
When you boss tells you “here, have a million transistors, make me a fast processor!” then you have numerous ways of achieving that goal. With the same number of transistors at their disposal a RISC and CISC designer will make different choices.
David A. Patterson of Berkeley is perhaps best known for popularizing the ideas of RISC processors with his paper: The Case for the Reduced Instruction Set Computer, published in 1980.
What Patterson outlines in this paper is not a detailed blueprint for how a chip should be made but more like philosophical guidelines.
- How much performance increase will adding this instruction give in real world programs?
- What are the hardware implications? Do we need to store a lot of complex state which makes context switching and Out-of-Order Execution more complex due to the need for storing lots of state?
- Could a combination of well designed simple instruction do the same job with comparable performance?
- Could we add this instruction by utilizing existing Arithmetic Logic Units (ALUs) and other resources found on the CPU, or do we need to add lots of new stuff?
- By not adding this instruction what are alternative usage of those transistors? More cache? Better branch predictor?
It is important to understand that these rules apply within a given transistor budget. If you got more transistors at your disposal you can add more instructions, maybe even complex instructions.
However the RISC philosophy prioritize keeping the ISA simple. That means a RISC designer will attempt to increase performance first through other means than adding instructions such as:
- Use transistors to add more cache
- More CPU registers
- Better pipeline
- Better branch predictor
- Superscalar architecture
- Add more instruction decoders
- Out of Order Execution
- Macro-operation fusion
- Compressed instructions
A key goal when designing a good RISC instruction-set (ISA) is thus to make the design such that it does not hinder future micro-architecture optimization.
That is different from how a CISC designer will design a CPU. A CISC designer will add complex instructions introducing more state to keep track of such as status registers if that gives better performance.
The Problem With CISC Design Philosophy
The problem is that CISC designers don’t think ahead. In the future your transistor budget may grow. Suddenly you got all these nice transistors you could use to create an Out-of-Order (OoO) superscalar processor logic. That means you are decoding multiple instructions each clock cycle and placing them in an instruction queue. Then the OoO logic figures out which instructions don’t depend on each other so they can run in parallel.
If you are a software developer you can think about the difference between functional programming and imperative programming. It can be tempting to mutate global data for short term performance gains. Yet once you run things in parallel having global state mutated by multiple functions which could be running in parallel in multiple threads becomes an absolute nightmare.
Functional programming prefers pure functions which only depend on inputs and no global data. These functions can easily run in parallel. The same mechanism applies to CPUs. Assembly code instructions which don’t depend on global state such as status registers can more easily run in parallel or in a pipeline.
RISC-V is a good example of this thinking. RISC-V does not have status registers. Comparison and jump instructions are rolled into one. You cannot catch integer overflow with status registers except by running extra calculation to determine if an overflow happened.
This should give you some clues about difference between RISC and CISC.
Priorities of a RISC Processor Designer
A RISC designers does not necessarily have a problem adding 10 new instructions if those don’t have significant impact on the micro-architecture. A RISC designer will be far more reluctant to add a single instruction if that instruction imposes a requirement to represent more global state in the CPU.
The end result of this philosophy is that historically it has been easier to add things like pipelines and super scalar architecture to RISC processors than CISC processors because one has avoided adding instructions introduce state management or control logic which makes it hard to add these kinds of micro-architecture innovations.
That is why the RISC-V team for instance prefers to do macro-operation fusion over adding instructions supporting things like complex addressing modes or integer overflow detection. If you don’t know what micro-operation fusion is have a look at these articles:
- What the Heck is a Micro-Operation?
- The Genius of RISC-V Microprocessors — Covers usage of macro-operation fusion in RISC-V
Now the RISC philosophy leads to particular design choices which keeps popping up which allows us to talk about some more concrete differences you will observe when comparing RISC and CISC processors. Let us look at those.
Characteristics of Modern RISC and CISC Processors
Certain design choices keep popping up across many different RISC processors. On common pattern is that RISC processors tend to have fixed length 32-bit instructions. There are a few exceptions such as AVR which uses fixed-length 16-bit instructions. An Intel x86 processor in contrast has 1 to 15 bytes long instructions. The Motorola 68k processor, another well known CISC design, had instructions which were 2 to 10 bytes long (16-bit to 80-bits).
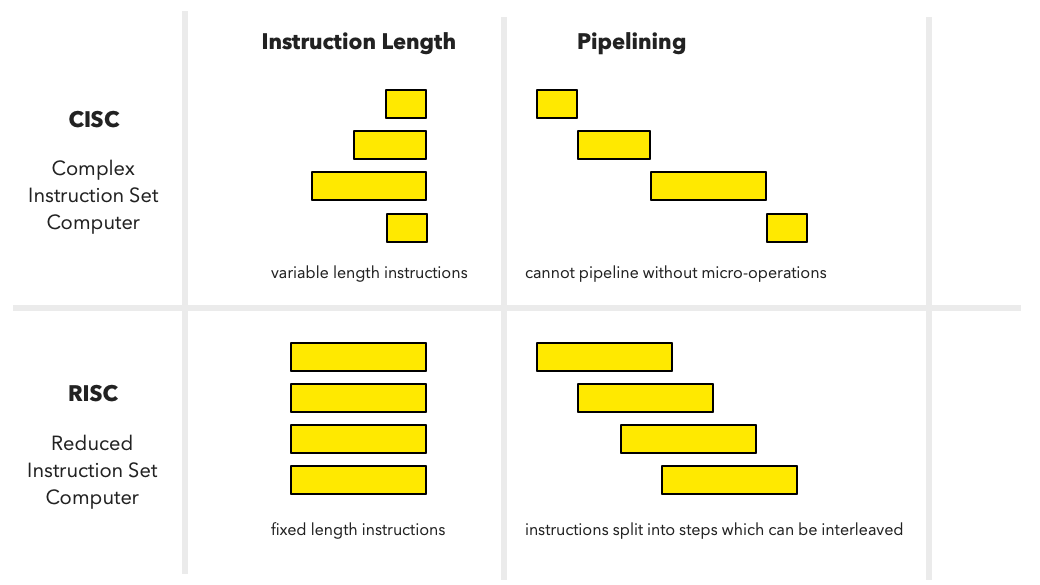
Variable length instructions is actually quite convenient for an assembly programmer. My first computer was an Amiga 1000 which had a Motorola 68k processors, so it introduced me to 68k assembly which was frankly quite neat. It had instructions for moving data from one memory location to the next, or you could move data from an address given by a register A1 to a memory location given by another register A2.
; 68k Assembly code
MOVE.B 4, 12 ; mem[4] → mem[12]
MOVE.B (A1), (A2) ; mem[A1] → mem[A2]Such instructions make the CPU easy to program, but it means there is no way to fit every supported instruction within 32-bits, because expressing a full source and destination address would consume 64 bits alone. Hence by having variable length instruction we can easily include full 32-bit memory addresses in any instruction.
However, this convenience comes at a cost. Variable length instructions are much harder to pipeline and if you want to make a superscalar processor decoding two or more instructions in parallel you cannot easily do it because you don’t know where each instruction begins and ends until you decode them.

If pipelining and superscalar sounds like gobbledygook then read these stories:
- Why Pipeline a Microprocessor? — What an instruction pipeline is and its benefits.
- Very Long Instruction Word Microprocessors — Explains superscalar microprocessors more in depth.
RISC processors tend avoid variable length instructions, because they break with the RISC philosophy of not adding instructions which make adding more advanced micro-architecture optimizations harder.
Fixed-length instructions cause inconveniences. You cannot fit memory addresses into any operation, only specific ones such as load and store instructions.
Load/Store Architecture
A machine code instruction has to encode information about what information is being performed such as whether it is doing an ADD, SUB or MUL. It also has to encode information about its inputs. What are the input registers and the output registers. Some instructions need to encode what address we are trying to load data from. In RISC-V instructions are encode like this:

The particular instruction we perform is called the opcode (yellow) and it consumes 7 bits. Every register input or output we specify requires 5 bits each. It should be clear from this that squeezing in a 32-bit address is impossible. Even a shorter address is hard because you need bits to specify registers which are used in the operation. With a CISC processor this isn’t a problem because you are free to make instructions which take more than 32-bits.
This tight space requirement causes RISC processors to have what we call Load/Store architectures. Only dedicated load and store instructions such as LW and SW on RISC-V can be used to access memory.
With a CISC processor, such as the 68k, almost any operation, such as ADD, SUB, AND and OR, could use a memory address as an operand (argument). In the example below 4(A2) computes to a memory address we use to read one of the operands (arguments) to the ADD instruction. The final result is stored there as well (on 68k destination is the right-argument).
; 68k assembly
ADD.L D3, 4(A2) ; D3 + mem[4 + A2] → mem[4 + A2]A typical RISC processor like one based on the RISC-V instruction-set would need to do the load (LW) and store (SW) to memory as separate instructions.
# RISC-V assembly
LW x4, 4(x2) # x4 ← mem[x2+4]
ADD x3, x4, x3 # x3 ← x4 + x3
SW x3, 4(x2) # x3 → mem[x2+4]You don’t need to compute an address by combining it with an address register (A0 to A7). You could just specify a memory address say 400 directly:
; 68k assembly
ADD.L 400, D4 ; mem[400] + D4 → D4But even a seemingly simply operation like this would require multiple RISC instructions.
# RISC-V assembly
LW x2, 400(x0) # x3 ← mem[x0 + 400]
ADD x4, x4, x3 # x4 ← x4 + x3The x0 register is always zero on a lot of RISC designs which means you can always use the offset plus base register form even if you are only interested in absolute memory addresses. While these offsets look very similar to what you do on the 68k, they are far more limited because you always need to fit into a 32-bit word. With 68k you can give a full 32-bit address to ADD.L. You can't with RISC-V LW and SW. Getting a full 32-bit address is quite cumbersome. Say you want to load data from the 32-bit address: 0x00042012, you would have to load the upper 20-bit and lower 12-bit separately to form a 32-bit address.
# RISC-V assembly
LUI x3, 0x42 # x3[31:12] ← 0x42 put in upper 20-bits
ADDI x3, x3, 0x12 # x3 ← x3 + x3 + 0x12
LW x4, 0(x3) # x4 ← mem[x3+0]Actually this could be simplified to: LUI x3, 0x42 LW x4, 0x12(x3)
I remember this annoying me a lot when I transitioned from 68k assembly to PowerPC (RISC processor previously used by Apple). At the time I though RISC meant everything would be much easier to do. I had found x86 to be messy and difficult to deal with. However, RISC isn’t as convenient for assembly coders to use as a good CISC instruction-set like the 68k. Fortunately there are some simple tricks to make this easier on a RISC processor. RISC-V defines a number of pseudo instructions to make assembly code writing easier. Using the LA (load address) pseudo instruction we can write the earlier code like this:
# RISC-V assembly with pseudo instructions
LI x3, 0x00042012 # Expands to a LUI and ADDI
LW x4, 0(x3)To summarize: While load/store architecture make writing assembly code more cumbersome it is what allows us to keep each instruction 32-bit long. That means creating a superscalar micro-architecture which can decode multiple instructions in parallel cost fewer transistors to implement. Pipelining each instruction becomes easier because most of them can fit in classic 5-step RISC pipeline.
RISC Processors have lots or Registers
With a fancy CISC processor like the 68k you could do a lot with an instruction. Say you want to copy numbers from one array to another. Here is a contrived example in C using pointers:
// C code
int data[4] = {4, 8, 1, 2, -1};
int *src = data;
while (*xs > 0)
*dst++ = *src++;If you store the pointer src in address register A0 and dst in address register A1 on the 68k processor you can do the copy and advance each pointer by 4 bytes all in just one instruction:
; 68k assembly
MOVE.L (A0)+,(A1)+ ; mem[A1++] → mem[A2++]That is just one example, but in general you can do a lot more with CISC instructions. That means you need less code. RISC designers thus realized their code would get bloated. So RISC designers analyzed real code to come up with schemes which would reduce code size without using complex instructions. What they discovered was a lot of code is simply to load and store data from memory. By adding lots of registers one could keep temporary results in registers without writing them out to memory. That would reduce the number of load and store instructions which need to be performed, which in turn would reduce code RISC code size.
For this reason MIPS, SPARC, Arm (64-bit) and RISC-V processors have 32 general purpose registers. We can contrast that with original x86 which only had 8 general purpose registers.

A RISC/CISC Perspective on Complexity
What I am trying to get across in this story is that a RISC processor is not less advanced than a CISC processor. The difference is where RISC and CISC designer choose to add complexity.
CISC designers put complexity in instruction-set architecture (ISA) while a RISC designer would rather add that complexity in their micro-architecture, but as I keep stressing they don’t want the ISA to impose complexity in the micro-architecture.
Let me do a comparison between the MIPS R4000, Motorola 68040 and Intel 486 to emphasize this difference in philosophy. They each had a ballpark of 1.2 million transistors and got released around the same time (1989 to 1991).
- The RISC processor (R4000) was 64-bit the others 32-bit.
- R4000 had 8-stage pipeline allowing much higher clock frequency than the 68040 with 6-stage and 486 with 5-stage pipeline.
- Longer pipeline gave R4000 from 100–200 Mhz way beyond the 40Mhz of the 68040 and the 486DX2 got to 66Mhz (100Mhz in a much later model).
Eventually one got faster CISC processors such as 68060 and Pentium in 1993/1994. But at the same time MIPS R8000 appeared which was a superscalar architecture which could decode 4 instructions in parallel. A Pentium could only decode 2 instructions per clock cycle.
So we can see how RISC designers favored fancier micro-architecture over fancier instructions.
“But Modern CISC Processors Have Complex Micro-Architecture!”
You may protest and say that CISC processors today have complex micro-architectures. Indeed they do. A modern Intel or AMD processor has multiple decoders, micro-operation cache, advanced branch predictors, Out-of-Order (OoO) execution engines. However, this is not surprising. Remember my key point about transistor budget philosophies: Everyone has a lot of transistors to play with today so all high-end chips will have a lot of advanced micro-architecture features. They can afford it with the budget they are given.
Here is the kicker: Many of these complex micro-architecture features are imposed by the complex CISC instruction-set. Let me give some examples. To make pipelines work x86 processor chop up their long complex instructions into micro-operations. Micro-operations are simple and behave more like RISC operations so they can more easily be pipelined.

The problem is that chopping up CISC instructions into simpler micro operations is not easy. Thus many modern superscalar x86 processors have 3 instruction decoders for simple instructions and 1 decoder for complex ones. Since you don’t know where each instruction starts and end a CISC processor has to engaged in a complex guessing game involving a lot of transistors.
A RISC processor avoids this complexity and can instead spend all those wasted transistors on adding more decoders or doing other optimizations such as using compressed instructions or macro-operation fusion (combine very simple instructions into more complex ones).

If you compare Apple’s M1 processor which is a RISC based processor with AMD and Intel processors you will notice it has far more instruction decoders. CISC designers try to alleviate this problem by adding micro-operation caches. With micro-operation caches a CISC processor does not have to go through the hurdle or decoding the same complex instructions over and over again. Yet adding this feature obviously costs transistors. It is not free. Thus you are blowing your transistor budget on micro-architecture complexity which is only required because of the complexity of your ISA.
Arm vs RISC-V Design Philosophy
One problem comparing modern RISC and CISC processors is that RISC has basically won. Nobody designs CISC processors from scratch anymore. x86 processors from Intel and AMD are popular today mainly because of backwards compatibility.
If you sat down a design team today and told them to design a high-performance processor from scratch then you would not end up with a traditional CISC design.
However, that does not mean there are not differences within the RISC community on how much designers lean in a CISC or RISC direction. Modern Arm processors and RISC-V based processors are interesting examples of this contrast.
Arm designers are more willing to add complex instructions to gain performance. Keep in mind that does not Arm is not a RISC design. As your transistor budget grows it is fair game add more complex instructions.
RISC-V designers are more keen on keeping complexity in the ISA minimal and instead increase complexity in the micro-architecture to gain performance by using tricks like compressed instructions and macro-operation fusion. I discuss these design choices here: The Genius of RISC-V Microprocessors.
The difference choices for Arm and RISC-V are not arbitrary but are heavily influenced by very different goals and markets. Arm is increasingly in higher-end markets. Keep in mind that Apple’s Arm chips are competing head to head with x86 chips and soon Nvidia will do the same.
RISC-V aims to be a much broader architecture to be used in anything from your keyboard, to AI accelerators, inside GPUs to specialized supercomputers. That means RISC-V means flexibility and the more complex instructions you add the more minimal complexity you impose, thus reducing freedom to tailor chips to a particular use-case.
Resources and Related Articles
Resources and related articles I have written on this topic.
What Does RISC and CISC Mean in 2020? — One of my first attempts at reflecting on this topic.
Philosophy of RISC — My first reflections on RISC being a philosophy of design rather than a checkbox list of features.
Advantages of RISC-V vector processing over x86 style SIMD — Advantages of doing data parallelism with vector processing instead of SIMD instructions.
IBM 801 — Regarded as the first RISC processor

